Practical Use: How I Use LLMs
Anyone who has talked to me over the last couple months -- since starting a contract at Google, when it was mandated I start using Antigravity -- has heard me say that I'm fully "AI-pilled." I've been using LLMs heavily for 5 months now, but working at Google has forced me to use them practically. This is a look at how I'm making use of these tools in my day to day. I don't have any authority to provide guidance here (I'm learning just like everybody else) but I've found a workflow that's working well and delivering strong results.
I touched upon this in my previous post Software Development in the Age of the LLM: "Spend 60% of time planning, 30% testing, 10% implementing," but I want to expand further as I go through the build process for a fresh project idea in real time. Focus on specs, gates, and what I think are the important things.
The Concept
I want to build a small tool that solves a problem that annoys me when planning trips with my opinionated friends. I don't like having to sit together, looking at Google Maps and Calendars, pitching different trip routes and itineraries. There's always a Google Doc that no one uses and a ton of different options saved across Google Maps, all shifting fluidly as we tweak dates and find fun side trips.
In my mind this is a hyper-collaborative tool that adapts to the fluidity of trip planning and enables consensus building. That's product-speak, in plain terms this is a tool that lets multiple people see a shared map and calendar and move things around in realtime. I'm going to call it "waypoint" because I have no better codename.
Planning
One more moment to hype Google's Antigravity IDE. It truly nails spec-driven development (sorry to AWS' Kiro editor, which fell incredibly short). I start with a model, make sure it's in planning mode, and start the iterative process of defining specifications and refinement. I know the basic idea and I have an idea of the components I want. Let's prompt:
I would like to build a tool for collaborative trip itinerary planning, including a map, a calendar, and a voting mechanism. The idea is that multiple people can select places on a map, propose routes, map them to calendar dates, and vote for either individual components or the whole plan.
This is how most of my plans start off. A structured prompt that contains a goal and an idea of how to get there. Because this is kicking off planning, it does not contain the success criteria or other constraints. Those will come later.
This process is extremely similar to how we drove design reviews at AWS. We start with HLDs (high level designs) that break the project apart into phases, we define a strong architecture and think extensibly, and we identify the core P0 featureset. We discuss tradeoffs, think about design patterns, analyze interactions across systems, and identify places where things will likely break. These are the things I think are most important to focus on when designing a system: the data model, the access model, and naming conventions. Most everything falls into one of those three categories at a high enough level. These also all factor into what is in my opinion the singlemost important consideration for scaling a system, caching. All of these will inform what we can cache, how we cache it, and for how long.
Data Model
Schema, data shapes, table design -- It's all essentially the same problem. What does our data look like? What fields do we need? How do they relate to each other? This is the most critical part of the design process with a new system. The shape of data will determine, essentially forever, how the system works and scales. Relations determine how performant database queries will be, how the UX will flow, and how extensible the system is for future unknown features. With the added layer of LLMs, our data needs to be even more intentional knowing that eventually it will be used to inform responses.
There are tons of patterns and constraints here: polymorphic relationships, indices to slice data in different ways, CQRS, ACID, nesting JSON, Event Sourcing, etc. This is a very deep specialization area on its own, and a place where some basic knowledge and vision can help us push the LLM in directions where we leverage its core strengths of deep research and training. It takes practice to understand the tradeoffs of each approach and to know when to use them, and it's worth asking the LLM "what is the best approach considering need x, constraint y, and goal z?"
Access Model
Once the data is shaped, we need to decide who can see and modify it. This is the Access Model. It covers authentication (who are you?) and authorization (what are you allowed to do?). In a collaborative tool like Waypoint, this means defining roles: who can propose a route, who can vote, and who has administrative rights to finalize the plan. Do we need granular row-level security so that a user can only delete their own comments?
When building AI-first applications, getting the access model right from the start is absolutely crucial. You are essentially building backend functions that an autonomous agent might invoke on behalf of a user. If your LLM has access to a deleteTripLeg function, the underlying API must strictly enforce that the current user actually owns that trip. You cannot rely on the LLM to enforce business logic around permissions. The LLM should only ever be aware of the data and actions available to the specific user context it is operating within.
Furthermore, your access model heavily dictates your caching strategy. Globally public data is easy to cache at the edge. Highly personalized, role-restricted data—like a private trip itinerary—requires complex, localized caching bounds to ensure rapid responses without accidentally leaking one group's plans to another.
Naming Conventions
What we choose to name our variables, our services, our classes generally will affect our lives from the moment they're put to paper. It's one of the hardest problems in computer science, and "convention over configuration" will set a codebase up for success for automation, extensibility, and for developer experience.
Descriptive, readable, cohesive naming is the foundation of how good code gets built. Good names can encode the business domain and other useful metadata, reducing cognitive load. Imagine a variable user = user.name. Who is the user and what are they trying to do in what part of the system? Compare that to TripOwner = user.name, we now have the metadata to show that this is an Owner of Trips.
Descriptive names can enforce testability and ensure that code can be added with more ease. Imagine a TripMap component for selecting places, and now we want to add our calendar... TripCalendar is a natural evolution. There is very little thought required, and it's a naturally extensible format. Now think about wanting to automate more of this: [Calendar, Map, Itinerary] to define components, and reusable tests to validate each of those iteratively. We could probably even generate components from a single base. Being able to nest conventions like this is key to keeping things intuitive from the start.
It sounds easy, but I could spend more time debating naming conventions at the start of a project than most other parts.
Working Example
With 60% of the time going to planning, I want to show what the process looks like and why so much time is spent here. Here is a list of comments I've made on three revisions of a new plan:
| # | Round | Selection Context | Comment |
|---|---|---|---|
| 1 | 1 | Collaboration model — how far do we go? | Let's build in phase 2, but knowing we need to build extensibly now and ultimately support auth, a db, and websockets. |
| 2 | 1 | Map tile provider & routing API | mapbox is my first instinct, but google maps would better allow us to integrate into the ecosystem. what are the tradeoffs? we want to be able to select specific points of interest along a route, find hotels, etc |
| 3 | 1 | Architecture Overview | keep in mind: itineraries have "legs", and we should be able to vote on specific legs. a leg is a subsection of an itinerary, and can be single day or multi day. trip -> itinerary (one or multiple) -> leg -> route, dates, etc |
| 4 | 2 | Verdict: Google Maps wins… | confirmed, use google maps |
| 5 | 2 | Architecture — Built for Phase 2 | We should also consider some LLM-powered improvements: leg recommendations (accept a start and an end destination and propose a route and points of interest), POI recommendations ("find cool stuff along this route"), i'm feeling lucky (propose cool trips based on a general area) |
| 6 | 2 | repository pattern | can you explain this pattern for my understanding? i am familiar with DAOs, and ORMs, and am curious what this pattern is, how we are using it, and why |
| 7 | 2 | interface ITripRepository | What is the industry standard usage of this pattern? CRUD methods on the interface? RESTful? |
| 8 | 3 | REST / Repository table | Does it make sense to name our methods CRUDfully? createTrip, readTrip, updateTrip, describeTrip? i truly do not know, I am asking what the industry standard conventions for this pattern are. |
| 9 | 3 | aggregate roots / getTrip() loads the full object graph | This means we need to focus on our relations? Trip hasMany legs? Should we model this? What if we move a leg between trips? |
| 10 | 3 | Phase 1 implementation will use OpenAI/Anthropic API… | let's just use gemini and stay in the ecosystem. but this should also be abstracted away behind providers we can swap out or fall back between |
And, for additional context, here is a running list from another project for the implementation of a graph database for tracking regulatory compliance requirements:
| # | Round | Selection Context | Comment |
|---|---|---|---|
| 1 | 1 | Phase numbering (started at Phase 3) | "why is phase 3 the beginning? phases should be scoped to a specific ADR" |
| 2 | 1 | Statute node type | "there is currently no concept of a 'statute' where is this coming from? how does it integrate with the larger system? is this US Section 404/Section 10? something else?" |
| 3 | 1 | Existing schema alignment | "we currently store the USACE NWPs in a table rule_sets with rule_definitions for conditions. we need to ensure we either match the existing schemas, or we migrate the old schemas to something newer and more extensible. what is the principal engineer's decision?" |
| 4 | 2 | Graph→PG naming convention | "naming should match as exactly as possible. we can use a prefix to delineate this is the graph as the data source, but overall, naming conventions should match exactly. in my opinion, what is the recommendation? this needs to be extensible, and built with a good developer experience for long term ops" |
| 5 | 2 | Statute storage (graph-only vs PG) | "should we backfill this into a pg table?" |
| 6 | 2 | Statute backfill approach | "we should backfill to postgres, graph options are better. what is the industry standard?" |
| 7 | 3 | PermitType vs permit_templates naming | "in this case, we should change the pg table name to match graph IMO. this is a better more descriptive name" |
| 8 | 3 | RuleSet naming (not Condition) | "the idea is that rule_sets can have multiple definitions, e.g. for a rules engine that validates drawings for a specific district" |
| 9 | 4 | Canonical operator set | "ensure this list is holistic, and matches exactly the industry standard. e.g. ensure true/false are captured, OR, AND, etc as needed" |
| 10 | 4 | Statute M2M recommendation (join table) | "sure" |
| 11 | 4 | Blast radius (~20 files) for rename | "some of these permit_templates may not even be used, we should clean up dead code and streamline this concept with this change." |
| 12 | 4 | Deploy coordination for rename | "no issues" |
| 13 | 4 | Entity resolution — LLM costs | "we already have tables of extracted chunks, what more do we need to do? we need to be extremely strategic about costs, and can leverage ollama locally to call gemma models if needed" |
| 14 | 4 | execute_read() org filtering performance | "performance impact?" |
| 15 | 4 | Seeded node status: confirmed | "nit: status CONFIRMED. enum for statuses, uppercase. this should always be our approach for enum fields like this" |
| 16 | 4 | GeographicScope from district_code | "district code and identifier are the primary cases. identifier is used more often" |
| 17 | 4 | Reconciler in graph/ module | "let's move this out of the graph and into its own module. in my opinion, this is best for extensibility." |
| 18 | 4 | Edge CRUD + traversal queries | "extra focus on performance here. algorithms need to be on point. please provide educational updates written to docs and runbooks as you go, i need to learn graphs" |
| 19 | 4 | Phase 2 risk description | "where is the risk?" |
| 20 | 4 | Open Q1: Statute M2M pattern | "approved" |
| 21 | 4 | Open Q2: PG trigger timing | "approved" |
| 22 | 4 | Open Q3: Aura provisioning timing | "phase 1 local completion" |
| 23 | 4 | Open Q4: Extraction test fixtures | "all of the 2026 NWPs, which we have already ingested for our current RAG" |
| 24 | 5 | "Zero additional LLM calls" claim | "we have already extracted all NWPs. this is a second LLM pass." |
Implementation
At 9:25a, I start the stopwatch.
Proceed. I will run all terminal commands that fail due to sandbox, permissions, or locks. Stop regularly to verify changes.
By 9:40a, with changes across 13 core files, I have a working prototype. It works: I can create a trip, I can add stops, I can select locations. With this first pass, I can see a number of basic UX issues: the data model is kind of weird. To me a trip should be able to have legs (leg 1 in Barcelona for 4 days, leg 2 in Madrid for 5), each leg can have x number of days with n number of places saved, and the connection between legs are routes, which can be any modality and have their own stops.
A quick rev to tweak our data model, and we are cruising. This goes into its own sub-plan:
Remove Itinerary interface: A Trip will now directly contain an ordered array of legs: Leg[].
Introduce Leg Types: A Leg will now be a discriminated union of DestinationLeg and RouteLeg.
Introduce TripDay: Destination legs will map out individual days automatically based on their date boundaries.
Validation
This is where our feedback loop begins.
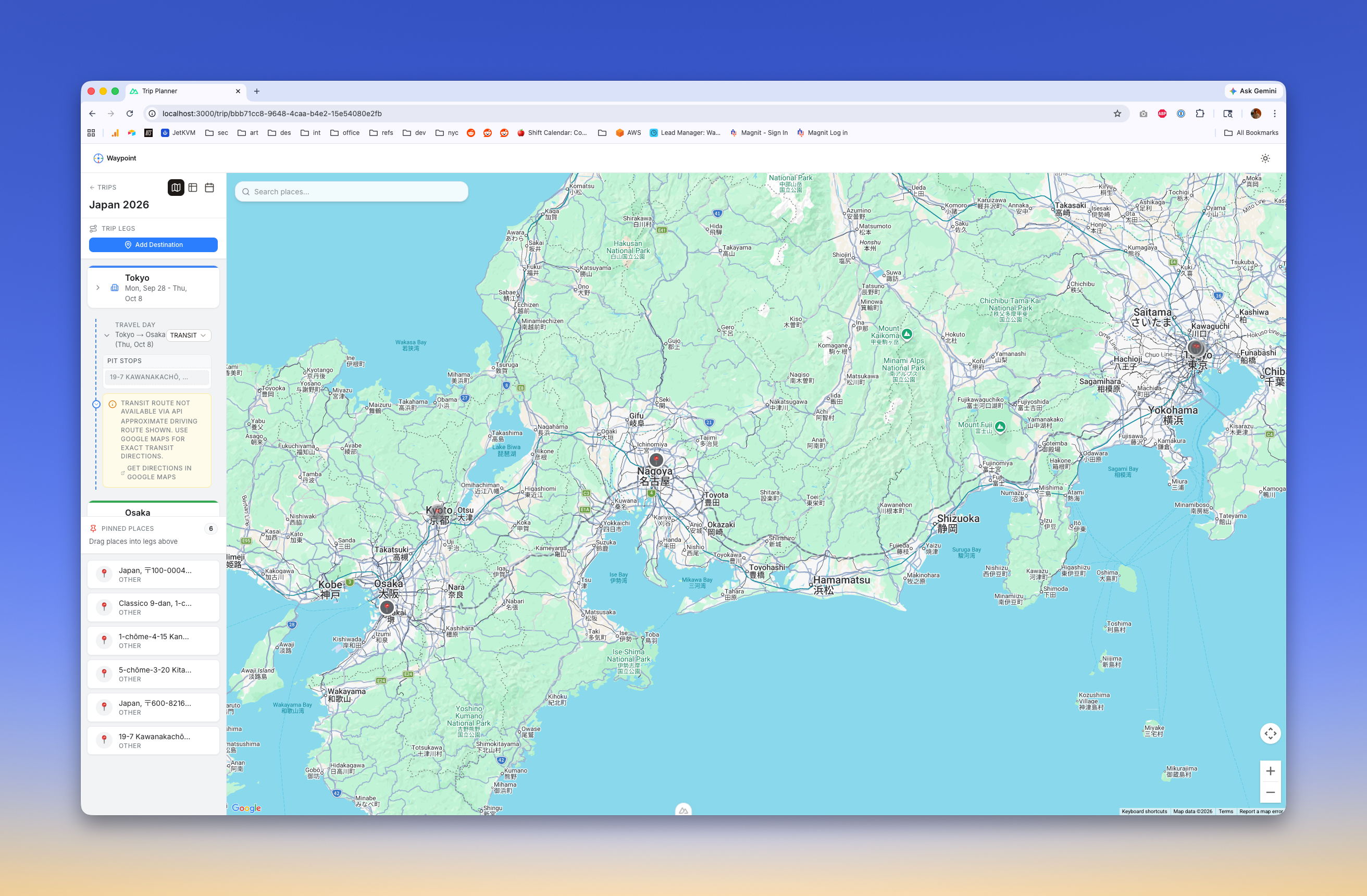
Clicking around the page reveals some perceived deficiencies: primarily, I can't get freaking train routes to work between legs in Japan, where I'm testing. All real weebs know that Shinkansen and trains are the only way to travel between cities (I've driven between Osaka and Fukuoka over two weeks, but that's an outlier, even to locals). If train routes aren't working, this is a failure to me.
I spend close to an hour here spinning, with repeated prompts along the lines of "no, wrong again" and "stop fucking up." I test against actual Google Maps on my phone, where trains work. I spend time digging in docs myself, along with Claude. And finally, after 5 or 6 attempts, Claude finds a caveat: Japanese train data is proprietary and is not available over API. Damn. We come up with a handful of alternatives like routing along roads which is our fallback and use stylization to emphasize that it's not true to train routes, add toasts with links to google maps, etc.
I quickly dig and find another product similar to this prototype called Wanderlog. It's complex, but it's nicely designed, and has a ton of features (shame on me for not researching first). I sign up and try to plan a similar Japan trip, and wow, the same issue. Wanderlog draws a road route and links to Google.
At this point, it's time build out automated tests. But because this is just a couple pages, I'm going to do the validation manually. This diverges from my normal approach, and I cannot stress enough the importance of guardrails when developing LLM-first, but it's just a weekend project.
11:00a, stop the stopwatch.
About an hour and a half all-in, not bad.
Learnings
Where we ran into the most issues:
- Data Models: Iteration always helps here, but a more thoroughly reviewed data model could have saved about 15 minutes, which is ~17% of the total time spent.
- Planning to Building Ratio: My 60% planning to 40% building and testing ratio was a bit off here. Closer to 50/50, time thinking through the data model would have reduced churn overall. Additionally, time researching implementation options for specific cases, like trains, could have shaved off ~33% of total time. An ounce of prevention...
- Bad API calls to various Google APIs: many APIs are deprecated in part or in whole, and this makes finding the correct endpoints to call for the data we need more troublesome than it could be.
- Design Tweaks: I did not provide much design direction in the spec (and I usually don't), usually deferring that process to a separate prompting session. This could be a detriment though, and it might be worth including some rough mocks in specs. To be honest, design is the one place I still see the need for expert humans in the dev process. There's no accounting for taste.
- Difficult to find information: Bad docs ultimately, and a place where LLMs with web searching tools can really shine.